NAG FL Interface
e02daf (dim2_spline_panel)
1
Purpose
e02daf forms a minimal, weighted least squares bicubic spline surface fit with prescribed knots to a given set of data points.
2
Specification
Fortran Interface
| Subroutine e02daf ( |
m, px, py, x, y, f, w, lamda, mu, point, npoint, dl, c, nc, ws, nws, eps, sigma, rank, ifail) |
| Integer, Intent (In) |
:: |
m, px, py, point(npoint), npoint, nc, nws |
| Integer, Intent (Inout) |
:: |
ifail |
| Integer, Intent (Out) |
:: |
rank |
| Real (Kind=nag_wp), Intent (In) |
:: |
x(m), y(m), f(m), w(m), eps |
| Real (Kind=nag_wp), Intent (Inout) |
:: |
lamda(px), mu(py) |
| Real (Kind=nag_wp), Intent (Out) |
:: |
dl(nc), c(nc), ws(nws), sigma |
|
C Header Interface
|
#include <nag.h>
| void |
e02daf_ (const Integer *m, const Integer *px, const Integer *py, const double x[], const double y[], const double f[], const double w[], double lamda[], double mu[], const Integer point[], const Integer *npoint, double dl[], double c[], const Integer *nc, double ws[], const Integer *nws, const double *eps, double *sigma, Integer *rank, Integer *ifail) |
|
C++ Header Interface
|
#include <nag.h> extern "C" {
| void |
e02daf_ (const Integer &m, const Integer &px, const Integer &py, const double x[], const double y[], const double f[], const double w[], double lamda[], double mu[], const Integer point[], const Integer &npoint, double dl[], double c[], const Integer &nc, double ws[], const Integer &nws, const double &eps, double &sigma, Integer &rank, Integer &ifail) |
}
|
The routine may be called by the names e02daf or nagf_fit_dim2_spline_panel.
3
Description
e02daf determines a bicubic spline fit
to the set of data points
with weights
, for
. The two sets of internal knots of the spline,
and
, associated with the variables
and
respectively, are prescribed by you. These knots can be thought of as dividing the data region of the
plane into panels (see
Figure 1 in
Section 5). A bicubic spline consists of a separate bicubic polynomial in each panel, the polynomials joining together with continuity up to the second derivative across the panel boundaries.
has the property that
, the sum of squares of its weighted residuals
, for
, where
is as small as possible for a bicubic spline with the given knot sets. The routine produces this minimized value of
and the coefficients
in the B-spline representation of
– see
Section 9.
e02def,
e02dff and
e02dhf are available to compute values and derivatives of the fitted spline from the coefficients
.
The least squares criterion is not always sufficient to determine the bicubic spline uniquely: there may be a whole family of splines which have the same minimum sum of squares. In these cases, the routine selects from this family the spline for which the sum of squares of the coefficients
is smallest: in other words, the minimal least squares solution. This choice, although arbitrary, reduces the risk of unwanted fluctuations in the spline fit. The method employed involves forming a system of
linear equations in the coefficients
and then computing its least squares solution, which will be the minimal least squares solution when appropriate. The basis of the method is described in
Hayes and Halliday (1974). The matrix of the equation is formed using a recurrence relation for B-splines which is numerically stable (see
Cox (1972) and
de Boor (1972) – the former contains the more elementary derivation but, unlike
de Boor (1972), does not cover the case of coincident knots). The least squares solution is also obtained in a stable manner by using orthogonal transformations, viz. a variant of Givens rotation (see
Gentleman (1973)). This requires only one row of the matrix to be stored at a time. Advantage is taken of the stepped-band structure which the matrix possesses when the data points are suitably ordered, there being at most sixteen nonzero elements in any row because of the definition of B-splines. First the matrix is reduced to upper triangular form and then the diagonal elements of this triangle are examined in turn. When an element is encountered whose square, divided by the mean squared weight, is less than a threshold
, it is replaced by zero and the rest of the elements in its row are reduced to zero by rotations with the remaining rows. The rank of the system is taken to be the number of nonzero diagonal elements in the final triangle, and the nonzero rows of this triangle are used to compute the minimal least squares solution. If all the diagonal elements are nonzero, the rank is equal to the number of coefficients
and the solution obtained is the ordinary least squares solution, which is unique in this case.
4
References
Cox M G (1972) The numerical evaluation of B-splines J. Inst. Math. Appl. 10 134–149
de Boor C (1972) On calculating with B-splines J. Approx. Theory 6 50–62
Gentleman W M (1973) Least squares computations by Givens transformations without square roots J. Inst. Math. Applic. 12 329–336
Hayes J G and Halliday J (1974) The least squares fitting of cubic spline surfaces to general data sets J. Inst. Math. Appl. 14 89–103
5
Arguments
-
1:
– Integer
Input
-
On entry: , the number of data points.
Constraint:
.
-
2:
– Integer
Input
-
3:
– Integer
Input
-
On entry: the total number of knots and associated with the variables and , respectively.
Constraint:
and
.
(They are such that
and
are the corresponding numbers of interior knots.) The running time and storage required by the routine are both minimized if the axes are labelled so that
py is the smaller of
px and
py.
-
4:
– Real (Kind=nag_wp) array
Input
-
5:
– Real (Kind=nag_wp) array
Input
-
6:
– Real (Kind=nag_wp) array
Input
-
On entry: the coordinates of the data point
, for
. The order of the data points is immaterial, but see the array
point.
-
7:
– Real (Kind=nag_wp) array
Input
-
On entry: the weight
of the
th data point. It is important to note the definition of weight implied by the equation
(1) in
Section 3, since it is also common usage to define weight as the square of this weight. In this routine, each
should be chosen inversely proportional to the (absolute) accuracy of the corresponding
, as expressed, for example, by the standard deviation or probable error of the
. When the
are all of the same accuracy, all the
may be set equal to
.
-
8:
– Real (Kind=nag_wp) array
Input/Output
-
On entry:
must contain the
th interior knot
associated with the variable
, for
. The knots must be in nondecreasing order and lie strictly within the range covered by the data values of
. A knot is a value of
at which the spline is allowed to be discontinuous in the third derivative with respect to
, though continuous up to the second derivative. This degree of continuity can be reduced, if you require, by the use of coincident knots, provided that no more than four knots are chosen to coincide at any point. Two, or three, coincident knots allow loss of continuity in, respectively, the second and first derivative with respect to
at the value of
at which they coincide. Four coincident knots split the spline surface into two independent parts. For choice of knots see
Section 9.
On exit: the interior knots
to
are unchanged, and the segments
and
contain additional (exterior) knots introduced by the routine in order to define the full set of B-splines required. The four knots in the first segment are all set equal to the lowest data value of
and the other four additional knots are all set equal to the highest value: there is experimental evidence that coincident end-knots are best for numerical accuracy. The complete array must be left undisturbed if
e02def or
e02dff is to be used subsequently.
-
9:
– Real (Kind=nag_wp) array
Input/Output
-
On entry: must contain the th interior knot associated with the variable , for .
On exit: the same remarks apply to
mu as to
lamda above, with
y replacing
x, and
replacing
.
-
10:
– Integer array
Input
-
On entry: indexing information usually provided by
e02zaf which enables the data points to be accessed in the order which produces the advantageous matrix structure mentioned in
Section 3. This order is such that, if the
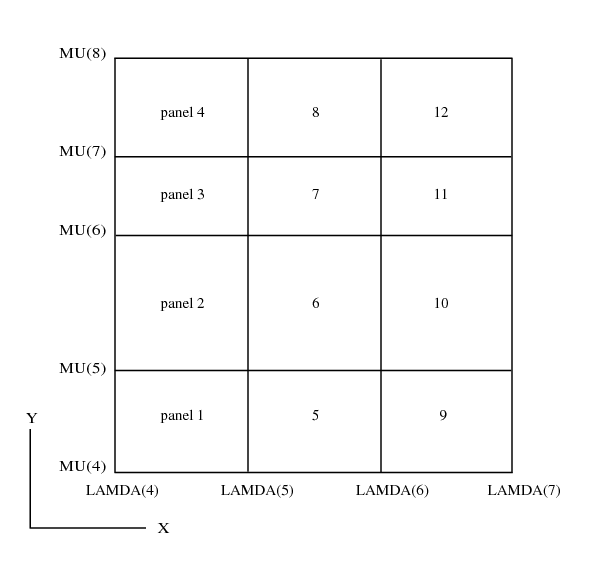
plane is thought of as being divided into rectangular panels by the two sets of knots, all data in a panel occur before data in succeeding panels, where the panels are numbered from bottom to top and then left to right with the usual arrangement of axes, as indicated in
Figure 1.
A data point lying exactly on one or more panel sides is considered to be in the highest numbered panel adjacent to the point.
e02zaf should be called to obtain the array
point, unless it is provided by other means.
-
11:
– Integer
Input
-
On entry: the dimension of the array
point as declared in the (sub)program from which
e02daf is called.
Constraint:
.
-
12:
– Real (Kind=nag_wp) array
Output
-
On exit: gives the squares of the diagonal elements of the reduced triangular matrix, divided by the mean squared weight. It includes those elements, less than
, which are treated as zero (see
Section 3).
-
13:
– Real (Kind=nag_wp) array
Output
-
On exit: gives the coefficients of the fit.
is the coefficient
of
Sections 3 and
9, for
and
. These coefficients are used by
e02def or
e02dff to calculate values of the fitted function.
-
14:
– Integer
Input
-
On entry: the value .
-
15:
– Real (Kind=nag_wp) array
Workspace
-
16:
– Integer
Input
-
On entry: the dimension of the array
ws as declared in the (sub)program from which
e02daf is called.
Constraint:
.
-
17:
– Real (Kind=nag_wp)
Input
-
On entry: a threshold
for determining the effective rank of the system of linear equations. The rank is determined as the number of elements of the array
dl which are nonzero. An element of
dl is regarded as zero if it is less than
.
Machine precision is a suitable value for
in most practical applications which have only
or
decimals accurate in data. If some coefficients of the fit prove to be very large compared with the data ordinates, this suggests that
should be increased so as to decrease the rank. The array
dl will give a guide to appropriate values of
to achieve this, as well as to the choice of
in other cases where some experimentation may be needed to determine a value which leads to a satisfactory fit.
-
18:
– Real (Kind=nag_wp)
Output
-
On exit:
, the weighted sum of squares of residuals. This is not computed from the individual residuals but from the right-hand sides of the orthogonally-transformed linear equations. For further details see page 97 of
Hayes and Halliday (1974). The two methods of computation are theoretically equivalent, but the results may differ because of rounding error.
-
19:
– Integer
Output
-
On exit: the rank of the system as determined by the value of the threshold
.
- The least squares solution is unique.
- The minimal least squares solution is computed.
-
20:
– Integer
Input/Output
-
On entry:
ifail must be set to
,
or
to set behaviour on detection of an error; these values have no effect when no error is detected.
A value of causes the printing of an error message and program execution will be halted; otherwise program execution continues. A value of means that an error message is printed while a value of means that it is not.
If halting is not appropriate, the value
or
is recommended. If message printing is undesirable, then the value
is recommended. Otherwise, the value
is recommended.
When the value or is used it is essential to test the value of ifail on exit.
On exit:
unless the routine detects an error or a warning has been flagged (see
Section 6).
6
Error Indicators and Warnings
If on entry
or
, explanatory error messages are output on the current error message unit (as defined by
x04aaf).
Errors or warnings detected by the routine:
-
At least one set of knots is not in nondecreasing order.
-
More than four knots coincide at a single point.
-
Array
point does not indicate the data points in panel order.
-
On entry, .
Constraint: .
On entry, , and .
Constraint: .
On entry, , , and .
Constraint: .
On entry,
nws is too small.
. Minimum possible dimension:
.
On entry, .
Constraint: .
On entry, .
Constraint: .
-
All the weights are zero, or rank determined as zero.
An unexpected error has been triggered by this routine. Please
contact
NAG.
See
Section 7 in the Introduction to the NAG Library FL Interface for further information.
Your licence key may have expired or may not have been installed correctly.
See
Section 8 in the Introduction to the NAG Library FL Interface for further information.
Dynamic memory allocation failed.
See
Section 9 in the Introduction to the NAG Library FL Interface for further information.
7
Accuracy
The computation of the B-splines and reduction of the observation matrix to triangular form are both numerically stable.
8
Parallelism and Performance
e02daf is not threaded in any implementation.
The time taken is approximately proportional to the number of data points, , and to .
The B-spline representation of the bicubic spline is
summed over
and over
. Here
and
denote normalized cubic B-splines, the former defined on the knots
and the latter on the knots
. For further details, see
Hayes and Halliday (1974) for bicubic splines and
de Boor (1972) for normalized B-splines.
The choice of the interior knots, which help to determine the spline's shape, must largely be a matter of trial and error. It is usually best to start with a small number of knots and, examining the fit at each stage, add a few knots at a time in places where the fit is particularly poor. In intervals of or where the surface represented by the data changes rapidly, in function value or derivatives, more knots will be needed than elsewhere. In some cases guidance can be obtained by analogy with the case of coincident knots: for example, just as three coincident knots can produce a discontinuity in slope, three close knots can produce rapid change in slope. Of course, such rapid changes in behaviour must be adequately represented by the data points, as indeed must the behaviour of the surface generally, if a satisfactory fit is to be achieved. When there is no rapid change in behaviour, equally-spaced knots will often suffice.
In all cases the fit should be examined graphically before it is accepted as satisfactory.
The fit obtained is not defined outside the rectangle
The reason for taking the extreme data values of
and
for these four knots is that, as is usual in data fitting, the fit cannot be expected to give satisfactory values outside the data region. If, nevertheless, you require values over a larger rectangle, this can be achieved by augmenting the data with two artificial data points
and
with zero weight, where
,
defines the enlarged rectangle. In the case when the data are adequate to make the least squares solution unique (
), this enlargement will not affect the fit over the original rectangle, except for possibly enlarged rounding errors, and will simply continue the bicubic polynomials in the panels bordering the rectangle out to the new boundaries: in other cases the fit will be affected. Even using the original rectangle there may be regions within it, particularly at its corners, which lie outside the data region and where, therefore, the fit will be unreliable. For example, if there is no data point in panel
of
Figure 1 in
Section 5, the least squares criterion leaves the spline indeterminate in this panel: the minimal spline determined by the subroutine in this case passes through the value zero at the point
.
10
Example
This example reads a value for
, and a set of data points, weights and knot positions. If there are more
knots than
knots, it interchanges the
and
axes. It calls
e02zaf to sort the data points into panel order,
e02daf to fit a bicubic spline to them, and
e02def to evaluate the spline at the data points.
Finally it prints:
-
–the weighted sum of squares of residuals computed from the linear equations;
-
–the rank determined by e02daf;
-
–data points, fitted values and residuals in panel order;
-
–the weighted sum of squares of the residuals; and
-
–the coefficients of the spline fit.
The program is written to handle any number of datasets.
Note: the data supplied in this example is
not typical of a realistic problem: the number of data points would normally be much larger (in which case the array dimensions and the value of
nws in the program would have to be increased); and the value of
would normally be much smaller on most machines (see
Section 5; the relatively large value of
has been chosen in order to illustrate a minimal least squares solution when
; in this example
).
10.1
Program Text
10.2
Program Data
10.3
Program Results